Структура и функционирование белков. Применение методов биоинформатики - Джон Ригден 2014
Пространственные мотивы
Обзор методов
Определение и подбор мотивов
Точки, образующие структурный мотив, определяются как атомы или псевдоатомы, полученные непосредственно из положения атомов в структуре. Геометрический центр боковой цепи, например, представляет собой псевдоатом с координатами, равными среднему арифметическому координат атомов в боковой цепи. При описании мотива используется до нескольких точек от каждого остатка, входящего в мотив, и все точки маркируются дополнительной информацией, такой как тип атома, тип остатка или физико-химические характеристики.
При проверке структуры на наличие совпадений со структурным мотивом используются количественные правила, указывающие, какая точка структуры с какой точкой мотива может быть сопоставлена, и геометрические пороговые значения, определяющие, какой набор точек обладает достаточным пространственным сходством, чтобы считаться совпадением (хитом). Степень точности этого совпадения также зависит от числа остатков и точек в мотиве. Существует компромисс между точностью совпадения и допускаемой величиной отклонения: желательно учитывать замену остатков, конформационную подвижность и низкое разрешение структуры, однако такой учет увеличит число биологически бессмысленных хитов и затруднит выделение среди них осмысленных. Включение определенных атомов в структурные мотивы призвано подчеркнуть локальные взаимодействия, например, водородные связи, в то время как использование геометрических центров функциональных групп или боковых цепей лучше приспособлено к подвижности и изменению типа остатка (Рис. 8.1). Представление симметричной боковой цепи, например, ароматического кольца в Phe, в виде одной точки также исключает необходимость сравнивать их различными способами (Oldfield 2002).
Поиск мотивов может быть трудоемок с вычислительной точки зрения, особенно если учесть, что может понадобиться сравнение тысяч структур с тысячами мотивов. Поиск структурных мотивов основывается на разработке эффективных алгоритмов, часто включающих одно или более из следующих действий:
1) Геометрическое хэширование. Хэширование - это широкий термин, описывающий приведение сложных данных к более простой форме, для которой сравнение может быть выполнено быстрее. Многочисленные величины, такие как расстояния, углы и типы атомов, могут быть редуцированы с помощью некой функции до нескольких чисел или даже до одного числа. Другие наборы значений, которые сводятся к такому же результату, соответствуют потенциально совпадающим подструктурам. Геометрическое хэширование кодирует пространственные соотношения между точками (Fischer et al. 1994), но также может включать и другие типы информации, например, физико-химические дескрипторы (Shulman-Peleg et al. 2004). Перед выполнением вычислительно затратных шагов по преобразованию групп и вычислению значений оценочных функций отдельные совпадения подструктур, которые предполагают сходные преобразования (перенос/вращение для совмещения соответствующих точек), могут быть объединены в более широкие группы (Pennec and Ayache 1998). Хэширование, или предварительная обработка данных, требует времени, но выполняется лишь один раз для каждой структуры и может сильно ускорить выполнение сравнений в целом.
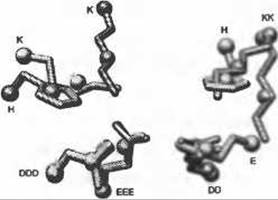
Рис. 8.1. (Цветную версию рисунка см. на вклейке.) Остатки каталитического центра членов надсемейства енолаз, иллюстрирующие аспекты представления мотивов и их специфичность. Для каждого из последующих белков показаны наложенные друг на друга боковые цепи двух основных и трех кислотных остатков: рацемаза миндальной кислоты (желтый, PDB 2mnr), енолаза (оранжево-розовый, PDB 4enl), метиласпартат-аммиак-лиаза (синий, PDB 1kcz). В виде шаров изображены положения альфа-углеродов и центра масс боковых цепей. Однобуквенный код, изображенный рядом с альфа-углеродами, обозначает различные типы остатков: Н - гистидин, К - лизин, D - аспарагиновая кислота, Е - глутаминовая кислота. Несмотря на то, что представленные в левом нижнем углу аминокислотные остатки высоко консервативны по типу и конформации, активный центр включает следующие изменения: (1) различные (хотя подобные) типы остатков на трех других позициях; (2) различные конформации боковой цепи, проиллюстрированные двумя лизинами справа; (3) различные положения в первичной структуре: основной остаток, изображенный вверху слева, является С-концевым у енолазы, но N-концевым в последовательности двух других белков. Использование центра масс боковой цепи, а не позиции функциональных атомов, обычно уменьшает чувствительность к изменениям в конформации и типах остатков. Учет атомов боковых цепей или центра масс (только не основной цепи) уменьшает допустимое отклонение в подвижности боковой цепи, но наоборот, обеспечивает большую специфичность в отношении точности расположения атомов в функциональном сайте. Учет атомов боковой цепи уменьшает степень чувствительности по отношению к случаям миграции функционального остатка, где важная боковая цепь может принадлежать аминокислотам, расположенным в разных местах первичной последовательности (Todd et al. 2002). Рисунок создан с помощью программы визуализации UCSF Chimera (Pettersen et al. 2004) (http://www.cgl.ucsf.edu/chimera)
2) Метод, основанный на теории графов. Граф состоит из вершин (точек) и ребер (линий, соединяющих пары вершин). Структура молекулы или структурный мотив может быть рассмотрен как маркированный граф. Например, атомы можно представить в виде вершин с промаркированным типом остатка и ребер, соединяющих каждую пару вершин, для каждого из которых приписываются соответствующие межатомные расстояния. С помощью алгоритма изоморфных подграфов производится поиск меньших графов и всех их ребер внутри более крупного графа. Такой алгоритм может применяться совместно с маркированием для поиска набора атомов в структурах, которые совпадают с типами атомов и межатомными расстояниями в структурных мотивах (Artymiuk et al. 1994; Spriggs et al. 2003). Допустимые отклонения в значениях позволяют сопоставлять похожие, но не идентичные расстояния. Определение клики графа (Schmitt et al. 2002) в конечном счете представляет собой аналогичную процедуру, но граф в этом случае описывает геометрию обеих структур вместе. В этом случае вершины графов представляют собой пары атомов или псевдоатомов, один из которых принадлежит структуре А, а другой - структуре В (“структурой” также может быть и структурный мотив). Образовать пары могут только одинаковые типы атомов. Две вершины соединяются ребром, если расстояние между двумя атомами в структуре А совпадает с расстоянием между атомами в структуре В в рамках допустимых отклонений. Клика представляет собой граф, в котором каждая вершина соединена со всеми другими вершинами. Таким образом, выявлением клик можно определить набор атомов структуры А с внутренними расстояниями, полностью совместимыми с теми, которые образованы парами атомов структуры В.
3) Поиск в глубину (англ. Depth-first search). Все структуры исследуются полностью на наличие структурного мотива. Пространство поиска определено ограничениями на типы атомов или остатков, которые можно совмещать, и геометрическими пороговыми значениями, такими как допустимые отклонения и верхняя граница суммарного среднеквадратичного отклонения (СКО).
Расширение совпадения. Сначала определяются частичные или затравочные совпадения с структурным мотивом, а затем предпринимаются попытки распространить совпадение на весь мотив целиком.
Все эти методы будут искать мотивы в данной статической структуре. Последние результаты показывают, что комбинирование алгоритмов поиска мотивов с МД расчетами, сэмплирующими конформационное пространство (см. тж. Главу 9), является многообещающим, хотя и вычислительно дорогим, путем к улучшению результатов поиска (Glazer et al. 2008).