Структура и функционирование белков. Применение методов биоинформатики - Джон Ригден 2014
Предсказание структуры мембранных белков
Предсказание топологии трансмембранных белков
Наборы данных, гомологичность, точность и перекрестная проверка
При разработке любых методов предсказания крайне важно как для обучения, так и для оценки достоверности результатов использовать данные высокого качества. Извлечение из доступных баз данных обучающей выборки представляет собой весьма трудоемкую задачу и требует принятия большого количества важных решений. В качестве примера рассмотрим поиск по базе данных PDB с использованием ключевого слова “трансмембранный”. Среди полученных в этом случае результатов будут как трансмембранные белки, закодированные в геноме, так и трансмембранные белки, не являющиеся нативными, например, пептид пчелиного яда 1ВН1, нарушающий структурную целостность бислоев, или бактериальный колицин ICІІ, который используется для образования пор в наружных мембранах конкурирующих бактерий. Более того, в базах данных довольно часто встречаются ошибки, которые привносят в метод искажения. В случае методов, основанных на машинном обучении, такие искажения не оказывают существенного влияния на результаты исследования. Для меньших по объему массивов данных эта проблема представляется более значимой.
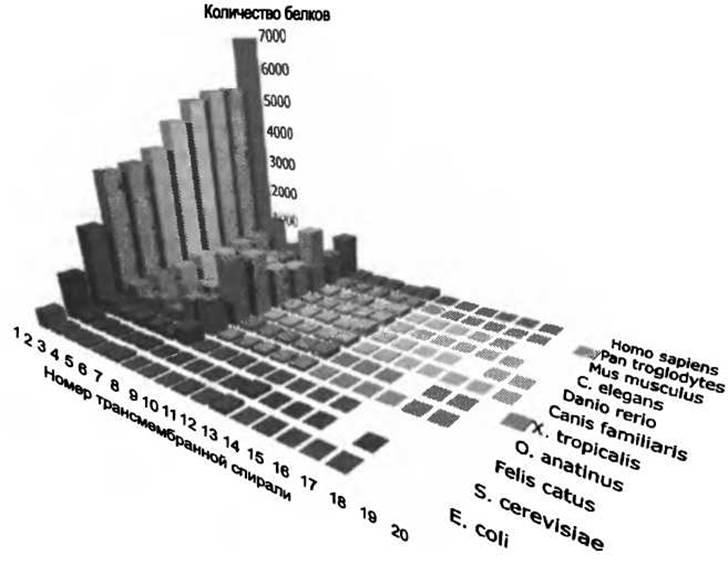
Рис. 4.6. Одиннадцать протеомов проанализированы с помощью метода дифференцировки трансмембранных/глобулярных белков MEMSAT3. Для белков, которые определены как трансмембранные, выполнено полное предсказание ТМ топологии. Ось абсцисс - номер трансмембранной спирали. Ось ординат - количество белков
Еще один вопрос, требующий рассмотрения, - это гомологичность последовательностей в выборках, которая для большинства случаев составляет 30-40% идентичности последовательностей. Поскольку данные о структурах ТМ белков сейчас вызывают повышенный интерес, для них этот показатель, возможно, несколько выше приведенного, который характерен, скорее, для выборок глобулярных белков. Несмотря на повышенный риск переобучения, или оверфиттинга, крайне важно использовать обучающие выборки достаточного размера. Для всех методов, основанных на машинном обучении, характерны множество свободных параметров и, как следствие, потенциальная возможность переобучения. Это значит, что вместо выявления некого паттерна последовательности алгоритм может заучить её “наизусть” со всеми возможными ошибками, которые она может содержать. Для переобученного метода характерно воспроизведение обучающих примеров с высокой точностью, в то время как в случае примеров, не встречавшихся ранее, метод будет малопригоден. Во избежание переобучения при оценке точности метода предсказания важно использовать обучающие и тестовые выборки с низкой гомологией.
Во всех случаях важно применять строгий скользящий контроль, или кросс-валидацию, достоверности данных. Скользящий контроль является статистическим методом и состоит в разделении исходной выборки на подвыборки меньшего размера. Каждая такая подвыборка проходит проверку на модели, настроенной с использованием остальных подвыборок. Процесс повторяется до тех пор, пока все подвыборки не пройдут проверку. При предсказании ТМ топологии наиболее часто используют два типа скользящего контроля. При контроле по К блокам (К-fold cross-validation) выборку делят на К подвыборок. Одну подвыборку из К, содержащую несколько последовательностей, принимают за тестовую выборку, а остальные К-1 подвыборок используют как обучающие. Процедуру повторяют К раз, при этом каждая из К подвыборок однократно используется в качестве тестовой. Затем полученные результаты (К штук) либо комбинируют, либо усредняют для получения общей оценки. Более строгий, хотя и более затратный с точки зрения вычислений тип скользящего контроля представляет собой контроль по отдельным объектам (LOOCV, leave-one-out cross-validation, кросс-валидация с исключенным элементом), также известный как критерий складного ножа (jack knife method). Этот метод предполагает использование одной последовательности из выборки в качестве тестовой, в то время как остальные последовательности составляют обучающую выборку. Процедура повторяется, пока каждая последовательность не пройдет однократную проверку. Этот метод представляет собой скользящий контроль по К блокам, где К равно числу последовательностей в выборке.
В некоторых исследованиях предпринимались попытки сравнить точность различных методов предсказания топологии трансмембранных белков (например, Melen et al. 2003), однако с тех пор сами методы были значительно усовершенствованы. В настоящее время принято считать, что при использовании лучших методов прогнозирования удается получить правильные топологии для 80-93% белков, хотя довольно сложно проводить оценку методов в отсутствие независимого скользящего контроля, в котором для проверки использовался бы общий набор данных. Методы могут отличаться высоким качеством прогнозов при тестировании на определенной выборке, например, на таком, который содержит небольшое количество сигнальных пептидов; при этом в случае массива данных, который содержит множество сигнальных пептидов, качество прогнозов может снижаться. Методы могут быть оптимизированы с использованием выборки, которая содержит множество слабо гидрофобных ТМ спиралей. В этом случае высоковероятна чрезмерная склонность методов к обнаружению ТМ спиралей в анализируемых массивах. На сегодняшний день наиболее качественные массивы данных, в которых топологии получены исключительно структурными методами, а степень гомологии снижена, содержат не более 150 последовательностей (Lomize et al. 2006b). Недостаточное согласование среди этих данных, а также нехватка необходимых данных скользящего контроля таким образом означают, что различия в точности используемых методов предсказания могут быть результатом различий в процессе обучения и проверки массивов данных, а не результатом заметных различий в качестве используемых подходов.