Основы биохимии Том 1 - А. Ленинджер 1985
Биомолекулы
Белки: ковалентная структура и биологические функции
Определение аминокислотной последовательности полипептидных цепей
Два больших открытия, сделанные в 1953 г., ознаменовали наступление новой эры в биохимии. В этом году Джеймс Д. Уотсон и Фрэнсис Крик в Кембридже (Англия) создали модель структуры ДНК (двойную спираль) и высказали предположение о структурной основе точной репликации ДНК. В этом предположении, но существу (хотя и не в явной форме), была выражена идея о том, что последовательность нуклеотидных звеньев ДНК содержит в себе закодированную генетическую информацию. В том же году Фредерик Сэнгер, работавший в Кембридже в той же лаборатории, расшифровал последовательность аминокислот в полипептидных цепях гормона инсулина. Это достижение само по себе имело большое значение, так как в течение долгого времени считалось, что определение аминокислотной последовательности полипептида представляет собой совершенно безнадежную по трудности задачу. Но, кроме того, результаты, полученные Сэнгером, практически одновременно с появлением гипотезы Уотсона-Крика, тоже наводили на мысль о существовании какой-то связи между нуклеотидной последовательностью ДНК и аминокислотной последовательностью белков. В следующее десятилетие эта идея привела к расшифровке всех содержащихся в ДНК и РНК нуклеотидных кодовых слов, которые однозначно определяют аминокислотную последовательность белковых молекул.
До работы Сэнгера. на выполнение которой ушло несколько лет, не было уверенности в том, что все молекулы данного белка являются строго идентичными по молекулярной массе и аминокислотному составу. В настоящее время известна аминокислотная последовательность многих сотен белков, выделенных из различных источников. Определение аминокислотной последовательности полипептидной цепи основано на принципах, которые впервые были развиты Сэнгером. Они используются еще и сегодня, правда со всевозможными вариациями и усовершенствованиями. Чтобы расшифровать аминокислотную последовательность любого полипептида, необходимо осуществить шесть основных стадий.
а. Стадия 1: определение аминокислотного состава
Первым шагом на пути к расшифровке аминокислотной последовательности служит гидролиз всех пептидных связей чистого полипептида. Образующаяся смесь аминокислот анализируется затем при помощи ионообменной хроматографии (разд. 5.18), что позволяет определить, какие аминокислоты и в каком соотношении присутствуют в гидролизате.
б. Стадия 2: идентификация амино- и карбоксиконцевых остатков
Следующий шаг состоит в идентификации аминокислотного остатка, находящегося на конце полипептидной цепи, несущего свободную а-аминогруппу, т. е. на аминоконце (МН2-конце, или N-конце). Для этой цели Сэнгер предложил использовать реагент, 1-фтор-2,4-динитробензол (разд. 5.22), который можно присоединить в качестве метки к аминоконцевому (N-концевому) остатку цепи, в результате чего образуется окрашенное в желтый цвет 2,4-динитрофенильное (ДНФ)-производное полипептида. При кислотном гидролизе все пептидные связи в таком ДНФ-производном полипептида расщепляются, однако ковалентная связь между 2,4-динитрофенильной группой и а-аминогруппой N-концевого остатка остается незатронутой. Следовательно, N-концевой остаток будет представлен в гидролизате в виде 2,4-динитрофенильного производного (рис. 6-6). Это производное легко отделить от незамещенных свободных аминокислот и идентифицировать хроматографическим способом путем сравнения его с аутентичными динитрофенильными производными различных аминокислот.
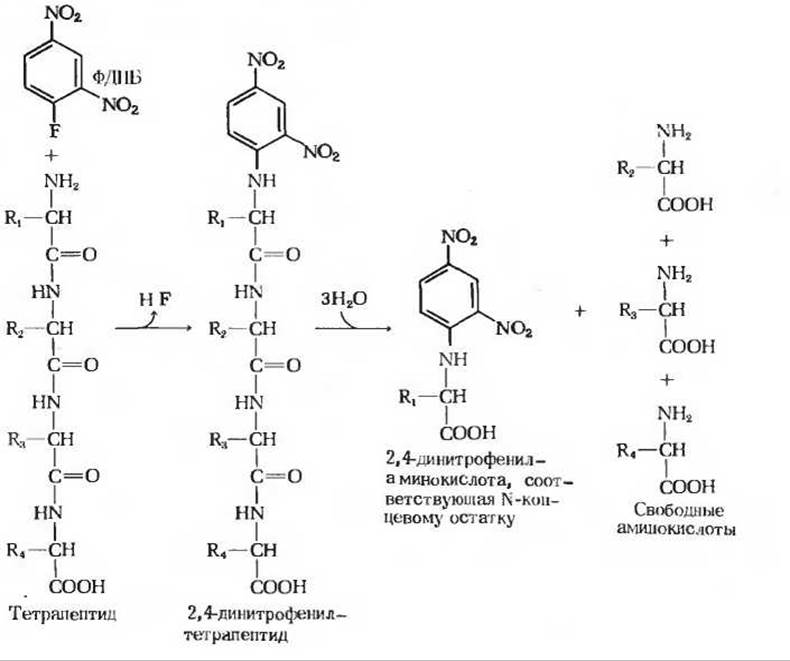
Рис. 6-6. Идентификация аминоконцевого остатка тетрапептида путем получения 2,4-динитрофенильного производного. Тетрапептид вступает в реакцию с 1-фтор-2,4-динитробензолом (ФДНБ) с образованием 2,4-динитрофенильного производного. Последнее подвергают затем кипячению в присутствии 6 н. НСl с тем, чтобы расщепить все пептидные связи. При этом аминоконцевая аминокислота остается в виде 2,4-динитрофен ильного производного.
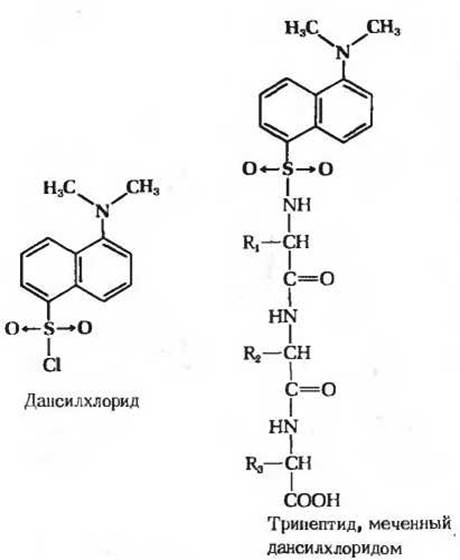
Рис. 6-7. Введение метки в аминоконцевой остаток трипептида с помощью дансилхлорида. После гидролитического расщепления всех пептидных связей дансильное производное аминоконцевой аминокислоты можно выделить и идентифицировать. Благодаря интенсивной флуоресценции дансильных групп они выявляются в значительно меньших количествах, чем динитрофенильные группы. Поэтому дансильный метод по чувствительности намного превосходит метод с использованием фтординитробензола.
Другим реагентом, используемым в качестве метки, позволяющей идентифицировать N-концевой остаток, служит дансилхлорид (рис. 6-7), который реагирует со свободной а-аминогруппой и дает дансильное производное. Последнее интенсивно флуоресцирует, вследствие чего его можно обнаружить и измерить при значительно более низких концентрациях, чем динитрофенильные производные.
Карбоксиконцевой (С-концевой) аминокислотный остаток полипептидной цепи тоже можно идентифицировать, используя тот или иной метод. Один из таких методов состоит в инкубировании полипептида с ферментом карбоксипептидазой, которая гидролизует только пептидную связь, находящуюся на карбоксильном конце (СООН-конце, или С-конце) цепи. Определив, какая из аминокислот первой отщепилась от полипептида при действии на него карбоксипептидазы, можно идентифицировать С-концевой остаток.
В результате идентификации N- и С- концевых остатков полипептида мы получаем две важные реперные точки для определения аминокислотной последовательности.
в. Стадия 3: расщепление полипептидной цепи на фрагменты
Теперь мы берем еще одну порцию анализируемого препарата, содержащего неповрежденные полипептидные цепи, и расщепляем их на более мелкие куски — короткие пептиды, состоящие в среднем из 10-15 аминокислотных остатков. Цель этой операции заключается в том, чтобы разделить полученные фрагменты и определить в каждом из них аминокислотную последовательность.
Для расщепления полипептидной цепи на отдельные фрагменты можно использовать несколько методов. Один из широко распространенных методов - это частичный ферментативный гидролиз полипептида под воздействием пищеварительного фермента трипсина. Каталитическое действие этого фермента отличается высокой специфичностью: гидролизу подвергаются только те пептидные связи, в образовании которых участвовала карбоксильная группа остатка лизина или аргинина независимо от длины и аминокислотной последовательности полипептидной цепи (табл. 6-6). Число более мелких пептидов, образующихся под действием трипсина, можно, следовательно, предсказать, исходя из общего числа остатков лизина и аргинина в исходном полипептиде. Полипептид, в котором содержатся пять остатков лизина и (или) аргинина, при расщеплении трипсином обычно дает шесть более мелких пептидов, причем все эти пептиды, за исключением одного, имеют на карбоксильном конце остаток лизина или аргинина. Фрагменты, полученные под действием трипсина, разделяют либо методом ионообменной хроматографии на колонке, либо при помощи электрофореза и хроматографии на бумаге; при этом часто проводят двумерное хроматографическое разделение пептидов на листе бумаги, в результате чего получают хроматограмму с распределившимися на ней пептидами в виде пептидной карты (рис. 6-8).
Таблица 6-6. Специфичность, свойственная четырем важным методам фрагментации полипептидных цепей
|
Обработка |
Точки растепления (остатки, которым принадлежит карбонильная группа расщепляемой пептидной связи) |
|
Трипсин |
Лизин Аргинин |
|
Химотрипсин |
Фенилаланин Триптофан Тирозин |
|
Пепсин |
Фенилаланин Триптофан Тирозин Некоторые другие остатки |
|
Бромциан |
Метионин |

Рис. 6-8. Пептидная карта, полученная после расщепления нормального гемоглобина человека трипсином. Каждое пятно содержит один из пептидов. Чтобы получить такую двумерную карту, смесь пептидов наносят на лист бумаги квадратной формы, проводят электрофорез в одном направлении, параллельном одной из сторон квадрата, после чего бумагу высушивают, а затем проводят хроматографическое разделение пептидов в другом направлении, перпендикулярном первому. Ни один из этих двух процессов в отдельности не позволяет разделить пептиды полностью, однако последовательное их осуществление оказывается очень эффективным способом разделения сложных пептидных смесей.
г. Стадия 4: определение последовательности пептидных фрагментов
На этой стадии устанавливается аминокислотная последовательность в каждом из пептидных фрагментов, полученных на стадии 3. Обычно для этой цели используют химический метод, разработанный Пером Эдманом. Расщепление по Эдману сводится к тому, что метится и отщепляется только N-концевой остаток пептида, а все остальные пептидные связи не затрагиваются (рис. 6-9). После идентификации отщепленного N-концевого остатка метка вводится в следующий, ставший теперь N-концевым остаток, который точно так же отщепляется, проходя через ту же серию реакций. Так, отщепляя этим способом остаток за остатком, можно определить всю аминокислотную последовательность пептида, используя для этой цели всего одну пробу. На рис. 6-9 показано, каким образом осуществляется расщепление по Эдману. Вначале пептид взаимодействует с фенилизотиоцианатом, который присоединяется к свободной а-аминогруппе N-концевого остатка. Обработка пептида холодной разбавленной кислотой приводит к отщеплению N-концевого остатка в виде фенилтиогидантоинового производного, которое можно идентифицировать хроматографическими методами. Остальная часть пептидной цепи после удаления N-концевого остатка оказывается неповрежденной. Укороченный пептид снова подвергается тойже серии реакций, что позволяет идентифицировать новый N-концевой остаток. Повторяя таким образом отщепление одного за другим N-концевых остатков, можно легко определить аминокислотную последовательность пептидов, состоящих из 10-20 остатков.
Определение аминокислотной последовательности проводится для всех пептидов, образовавшихся под действием трипсина. После этого сразу же возникает новая проблема - определить, в каком порядке трипсиновые фрагменты располагались в первоначальной полипептидной цепи.
д. Стадия 5: расщепление исходной полипептидной цепи еще одним способом
Чтобы установить порядок расположения пептидных фрагментов, образовавшихся под действием трипсина, берут новую порцию препарата исходного полипептида и расщепляют его на более мелкие фрагменты каким-либо иным способом, при помощи которого расщепляются пептидные связи, устойчивые к действию трипсина. В этом случае более предпочтительным часто оказывается не ферментативный, а химический метод. Особенно хорошие результаты дает реагент бромциан, расщепляющий только те пептидные связи, в которых карбонильная группа принадлежит остатку метионина (табл. 6-6). Следовательно, если полипептид содержит восемь остатков метионина, то при обработке бромшаном обычно образуются девять пептидных фрагментов. Полученные таким способом фрагменты можно разделить методом электрофореза или хроматографии. Каждый из этих коротких пептидов подвергают расщеплению по Эдману, как было описано для стадии 4, и таким путем устанавливают их аминокислотную последовательность.
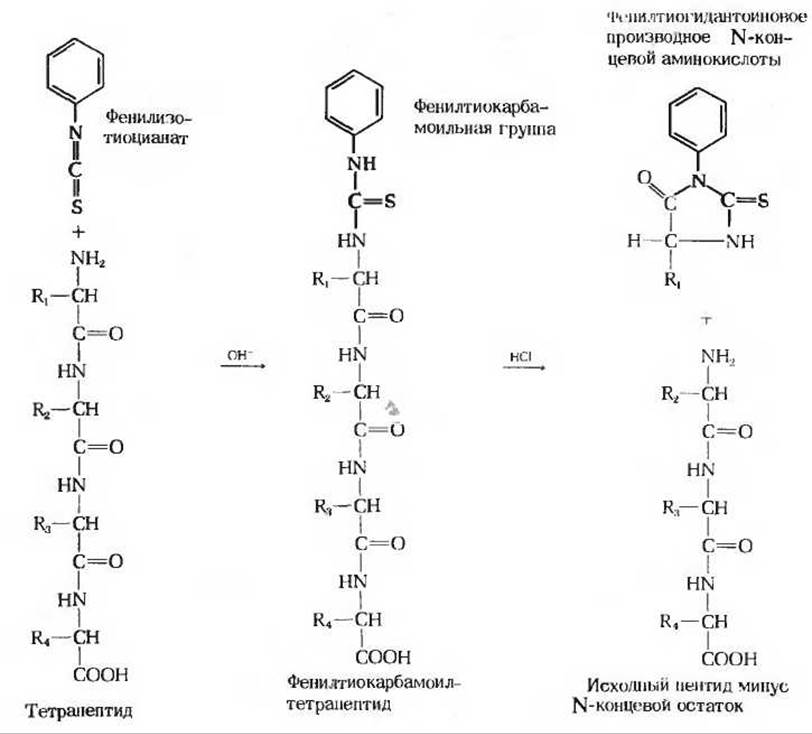
Рис. 6-9. Схема определения аминокислотной последовательности пептида путем его расщепления по Эдману. Исходный тетрапептид вступает в реакцию с фенил изотиоцианатом, в результате чего образуется фенилтиокарбамоильное производное аминоконцевого остатка. Этот остаток отщепляют от пептида без разрыва других пептидных связей и получают в виде фенилтиогидантоинового производного, которое можно идентифицировать хроматографическим способом. Оставшийся трипептид вновь проводят через тот же цикл реакций, что позволяет идентифицировать второй остаток. Эти операции повторяют до тех пор, пока не будут идентифицированы все остатки.
Итак, мы получили два набора пептидных фрагментов - один после обработки исходного полипептида трипсином и другой после химического расщепления того же полипептида бромцианом. Мы знаем также аминокислотную последовательность каждого пептида, входящего в состав этих двух наборов.

Рис. 6-10. Расположение пептидных фрагментов в правильном порядке на основе данных по перекрывающимся участкам. В приведенном здесь примере полипептид, состоящий из 16 аминокислотных остатков, после идентификации N- и С-концевых остатков был подвергнут фрагментации двумя способами. Вверху показаны полученные фрагменты, а внизу воссоздание полной последовательности полипептида по перекрывающимся участкам.
е. Стадия 6: установление порядка расположения пептидных фрагментов по перекрывающимся участкам
Теперь сравнивают аминокислотные последовательности в пептидных фрагментах, полученных двумя способами из исходного полипептида, чтобы во втором наборе найти пептиды, в которых бы последовательности отдельных участков перекрывались (т.е. совпадали) с последовательностями тех или иных участков в пептидах первого набора. Принцип расположения пептидов показан на рис. 6-10. Пептиды из второго набора с перекрывающимися последовательностями позволяют соединить в правильном порядке пептидные фрагменты, полученные в результате первого расщепления исходной полипептидной цепи. Более того, эти два набора фрагментов позволяют выявить возможные ошибки в определении аминокислотной последовательности каждого фрагмента.
Иногда второго расщепления полипептида на фрагменты оказывается недостаточно, чтобы найти перекрывающиеся участки для двух или более пептидов, полученных после первого расщепления. В этом случае применяется третий, а то и четвертый способ расщепления, что позволяет в конце концов получить набор пептидов, обеспечивающих перекрывание всех участков, необходимых для установления полной последовательности исходной цепи. При этом для расщепления полипептида можно использовать другие протеолитические ферменты, например химотрипсин или пепсин; правда, эти ферменты расщепляют пептидные связи гораздо менее избирательно, чем трипсин (табл. 6-6).