Основы биоинформатики - Огурцов А.Н. 2013
Основания биоинформатики
Биологические последовательности
Информация в молекулярной биологии
В информационном архиве (геноме) каждого организма содержится детальный план будущего развития и функционирования этого индивидуума. Молекулы ДНК - это длинные, линейные, цепочечные молекулы, представляющие собой строки, записанные четырёхбуквенным алфавитом (рисунок 6)
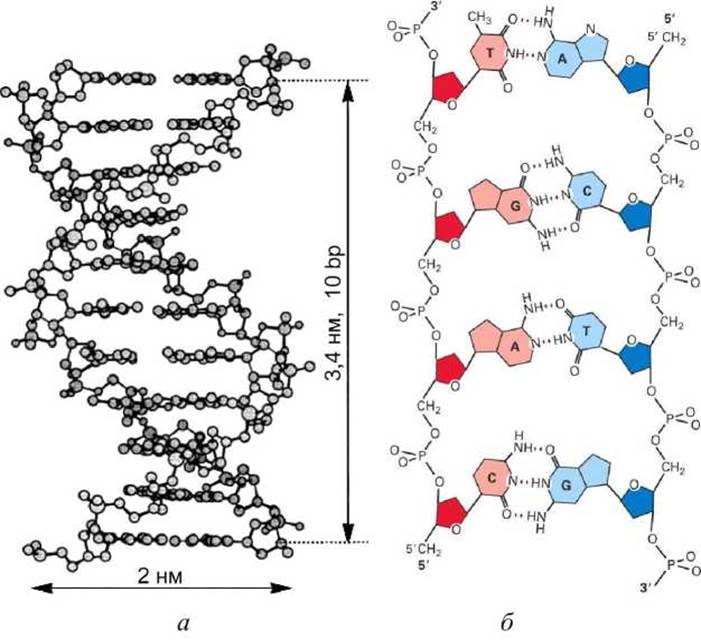
Рисунок 6 - Схема строения ДНК: а - ван-дер-ваальсовая модель, б - схема химических связей в ДНК
Даже геномы микроорганизмов представляют собой очень длинные строки, обычно состоящие из миллионов букв. При записи любой нуклеиновой кислоты в виде строки символов принято изображать нуклеотиды строчными английскими буквами:
![]()
В структуре ДНК полностью оговорены механизмы репликации и переноса информации с гена на белок. Почти безупречная репликация необходима для стабильности наследственности. Небольшая неточность в репликации, как и механизм импорта инородного генетического материала, также необходима, иначе организмы, не имеющие полового размножения, не могли бы эволюционировать. Цепи двойной спирали антипараллельны. Концы носят названия 3' и 5' по позициям в дезоксирибозном кольце. При транскрипции ДНК считывается в направлении от 3' к 5', а при трансляции мРНК считывается в направлении от 5' к 3' (см. [7], п. 2.1 и 5.1). Генетическая информация реализуется через синтез РНК и белков. Белки - это молекулы, отвечающие за жизнедеятельность большинства структур организма. Наши волосы, мышцы, пищеварительная система, рецепторы и антитела - все это белки. Как и нуклеиновые кислоты, белки
- это длинные линейные цепочечные полимеры, состоящие из мономеров
- аминокислот. Двадцать природных (протеиногенных) аминокислот по полярности бокового радикала можно разделить на неполярные, полярные и заряженные.
Мы будем использовать однобуквенные обозначения аминокислот прописными латинскими буквами следующим образом:
|
Неполярные аминокислоты: |
||
|
G - глицин (Gly) |
А - аланин (Ala) |
Р - пролин (Pro) |
|
V - валин (Val) |
I - изолейцин (Не) |
L - лейцин (Leu) |
|
F - фенилаланин (Phe) |
М - метионин (Met) |
|
|
Полярные аминокислоты: |
||
|
S - серин (Ser) |
С - цистеин (Cys) |
Т - треонин (Thr) |
|
N - аспарагин (Asn) |
Q - глутамин (Gln) |
Y - тирозин (Туr) |
|
W - триптофан (Тrр) |
||
|
Заряженные аминокислоты: |
||
|
D - аспарагиновая кислота (Asp) |
К - лизин (Lys) |
|
|
Е - глутаминовая кислота (Glu) |
R - аргинин (Arg). |
|
Генетический код - это шифр: триплеты букв из последовательности ДНК обозначают аминокислоты (таблица 2).
Таблица 2 - Стандартный генетический код
|
Первый нуклеотид |
Второй нуклеотид |
Третий нуклеотид |
|||
|
u |
c |
а |
g |
||
|
u |
Phe |
Ser |
Tyr |
Cys |
u |
|
Phe |
Ser |
Tyr |
Cys |
с |
|
|
Leu |
Ser |
STOP |
STOP |
а |
|
|
Leu |
Ser |
STOP |
Trp |
g |
|
|
с |
Leu |
Pro |
His |
Arg |
u |
|
Leu |
Pro |
His |
Arg |
с |
|
|
Leu |
Pro |
Gln |
Arg |
а |
|
|
Leu |
Pro |
Gln |
Arg |
g |
|
|
а |
Ile |
Thr |
Asn |
Ser |
u |
|
Ile |
Thr |
Asn |
Ser |
с |
|
|
Ile |
Thr |
Lys |
Arg |
а |
|
|
Met (START) |
Thr |
Lys |
Arg |
g |
|
|
д |
Val |
Ala |
Asp |
Gly |
u |
|
Val |
Ala |
Asp |
Gly |
с |
|
|
Val |
Ala |
Glu |
Gly |
а |
|
|
Val |
Ala |
Glu |
Gly |
g |
|
В участках ДНК зашифрованы аминокислотные последовательности белков. Обычно белки состоят из 200-400 аминокислот, что требует 600-1200 нуклеотидов ДНК для их кодирования. Синтез молекул РНК, например, РНК-компонентов рибосом, также определяется последовательностью нуклеотидов в ДНК. Однако в большинстве организмов не вся ДНК кодирует РНК или белки. Некоторые участки последовательности ДНК существуют для управления процессами транскрипции и репликации, а большая часть генома всё ещё не исследована и её функции пока не известны. Молекулы ДНК, содержащие стандартные четыре "нуклеотидные" буквы (а, с, g, t), сходны по химическому строению, а сама пространственная структура молекулы ДНК в первом приближении однородна.
Белкам же, наоборот, свойственно большое разнообразие трёхмерных конформаций. Эти конформации необходимы белкам для выполнения их разнообразных структурных и функциональных ролей. Последовательность аминокислот в белке - первичная структура белка - определяет его трёхмерную структуру. Для каждой природной аминокислотной последовательности существует уникальное стабильное нативное состояние - третичная структура, - в которое эта последовательность спонтанно переходит в нормальных условиях (см. [9], п. 4.3).
Если очищенный белок нагреть или каким-нибудь другим образом перевести в условия, которые сильно отличаются от естественных физиологических условий организма, то он "разворачивается", денатурирует, образуя беспорядочную биологически неактивную структуру. Именно поэтому в нашем организме существуют механизмы для поддержания относительно постоянных внутренних условий (см. [13], п. 2.4).
При восстановлении же нормальных условий полипептидные молекулы вновь приобретают свою функциональную третичную структуру, которая неотличима от нативной структуры природного происхождения (см. [9], п. 4.5).
Спонтанное сворачивание белков - фолдинг — с целью формирования их нативной структуры является точкой, в которой Природа совершает гигантский прыжок от одномерных генетических и пептидных последовательностей к трёхмерному миру, в котором мы все живем.
Однако существует следующий парадокс.
С одной стороны, трансляцию последовательностей ДНК в последовательности аминокислот очень легко описать логически - она определяется генетическим кодом. А сворачивание полипептидной цепи в точно определенную трехмерную структуру очень трудно описать логически. С другой стороны, для осуществления трансляции необходимы исключительно сложный механизм работы рибосомы, транспортные РНК (тРНК) и связанные с ними молекулы (см. [7], п. 5). А сворачивание белков происходит самопроизвольно без посторонней помощи (см. [9], п. 4.5).
Функции белков зависят от приобретения ими нативной третичной структуры. Например, нативная структура фермента может иметь на своей поверхности впадину (активный центр), которая связывает одну малую молекулу субстрата и помещает её рядом с аминокислотными остатками каталитического центра.
Таким образом, мы имеем следующие информационно-управляемые зависимости:
✵ Последовательность нуклеотидов ДНК определяет последовательность аминокислот белка.
✵ Последовательность аминокислот определяет структуру белка.
✵ Структура белка определяет его функцию.
В большинстве своём биоинформатика как раз и занимается анализом данных, связанных с этими процессами.
На данный момент эта парадигма не охватывает уровни выше, чем молекулярный уровень структуры и организации. В том числе, например, из поля зрения выпадают такие вопросы, как специализация тканей во время развития или, в более обобщённом смысле, влияние условий окружающей среды на генетические события.
В некоторых тривиальных случаях простых обратных связей легко понять молекулярные механизмы того, как увеличение количества субстрата приводит к повышению продуктивности фермента, который катализирует трансформацию этого субстрата (см. [9], п. 15.1). Более сложными являются программы развития организма в течение его жизни.
Эти фундаментальные вопросы о потоке информации и регуляции этого потока внутри организма сейчас начинают активно изучаться методами биоинформатики.