Принципы структурной организации белков - Г. Шульц 1982
Аминокислоты
Коллинеарная взаимосвязь между нуклеиновыми кислотами и полипептидами
Определение нуклеотидной последовательности ДНК может стать мощным методом определения аминокислотной последовательности белков. Генетический код является вырожденным в том смысле, что большая часть аминокислот описывается более чем одним кодоном. Поэтому нельзя установить нуклеотидную последовательность по коллинеарной аминокислотной последовательности. Однако удается извлечь информацию о неизвестной аминокислотной последовательности белка, анализируя исходную нуклеотидную последовательность. Реализация этого косвенного метода наталкивается на серьезное препятствие: экспериментальные ошибки, отвечающие делециям и вставкам отдельных нуклеотидов в полинуклеотидной последовательности, настолько нарушают порядок нуклеотидных триплетов, что правильное определение аминокислот оказывается пока не возможным.
Это наглядно иллюстрируется одной из последних работ [11] по белку оболочки вируса табачной мозаики, где определялась последовательность во фрагменте РНК; эта нуклеотидная последовательность была переведена в аминокислотную, которую в свою очередь можно сравнить с экспериментально найденными аминокислотами. Как видно из рис. 1.6, эти два полипептида никоим образом не идентичны ни по аминокислотной последовательности, ни по составу аминокислот.
Возможность определения последовательности полипептида по последовательности коллинеарной нуклеиновой кислоты представляет не только чисто теоретический интерес. Дело в том, что в настоящее время особенно велик прогресс как в накоплении генетического материала, так и в расшифровке последовательности нуклеиновых кислот; в то же время многие важные белки удается получить пока еще лишь в ничтожных количествах. Полный анализ последовательности полинуклеотида, сопровождающийся исследованиями фрагментов последовательности коллинеарной полипептидной цепи для гарантии правильности фаз трансляции, может стать полезным методом определения первичной структуры белков [12].
Некоторые сегменты ДНК кодируют более чем один белок. Коллинеарность аминокислотных и нуклеотидных поледовательностей привлекла особое внимание после сообщения о полной первичной структуре РНК, выделенной из вируса MS2 [13], и о ДНК, выделенной из вируса —X174 [12]. Бактериальные вирусы MS2 и —X174 — первые «живые» частицы, для которых была выяснена полная химическая структура генетического материала.
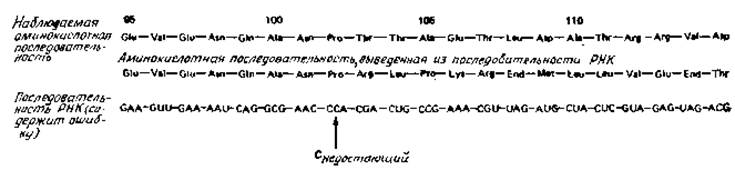
Рис. 1.6. Установление аминокислотной последовательности по соответствующей нуклеотидной последовательности. В первой строке показан сегмент аминокислотной последовательности белка оболочки вируса табачной мозаики, а в третьей — соответствующая последовательность РНК [11].
Одна ошибка в последовательности ведет к неправильной аминокислотной последовательности (см. вторую строку), начиная от остатка 103. Ошибка, по-видимому, заключается в отсутствие С в отмеченном положении, так как при наличии С большая часть последующих аминокислот приобретает правильный порядок. Такне ошибки, связанные со «сдвигом рамки» часто обнаруживаются по появленню в неожиданном положении кодонов End (вторая строка).
ДНК —X174 длиной в 5375 нуклеотидов содержит перекрывающуюся генную систему [14]: два белка считываются с одной и той же последовательности ДНК, но в различных фазах (рис. 1.7). Это означает, что общее число аминокислотных остатков в последовательности белка может быть больше, чем только одна треть от числа кодирующих ее нуклеотидов. Вопрос, наблюдается ли перекрывание генов в других прокариотных или эукариотных организмах, остается пока открытым.
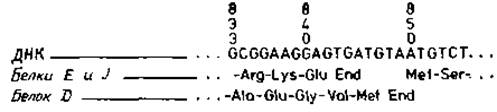
Рис. 1.7. Перекрывание нуклеотидных последовательностей различных генов [12]. Показан сегмент 833—855 генома бактериофага φX174. В этом геноме последовательность 850—963 кодирует белок J, последовательность 392—847 кодируют белок D и последовательность 570—842 — белок Е. Таким образом, нуклеотидная последовательность, кодирующая белок Е, полностью входит в область, кодирующую белок D, однако считывается в другой системе (строки 2 и 3). Кроме того, конец кодона D перекрывает начало кодона белка J в положении 850.