Принципы структурной организации белков - Г. Шульц 1982
Аминокислоты
Почему именно эти аминокислоты?
По-видимому, жизнь начиналась не с белков, а с автокаталитических нуклеиновых кислот. Ответить на вопрос, почему белки оказались построенными из аминокислот, приведенных в табл. 1.1, пока еще нельзя. Однако некоторые гипотезы могут приблизить нас к пониманию проблемы. Обсудим вначале основную организационную схему происхождения жизни. Наиболее вероятно, что жизнь началась с простых автокаталитических, т. е. самовоспроизводящихся молекул [3]. Именно нуклеиновые кислоты, а не белки, способны выполнять эту роль [4—6], поскольку однонитевые нуклеиновые кислоты могут использовать спаривание оснований для выстраивания комплементарной последовательности нуклеотидов. При объединении выстроенных нуклеотидов две нити могут образовывать энергетически выгодную двойную спираль Уотсона — Крика. В следующем цикле, после развертывания двойной спирали, комплементарная нить может репродуцировать исходную. Оба фактора, точный отбор последовательности путем спаривания оснований и энергетически выгодное образование двойной спирали, безусловно, способствовали автокаталитическому воспроизведению. Напротив, исходить из белка вместо нуклеиновой кислоты было бы значительно сложнее с точки зрения единой организационной схемы, поскольку взаимного опознавания аминокислот не существует.
Таблица 1.1 Обозначение и свойства 20 канонических аминокислотных остатков белкова
|
Аминокислота или ее остаток |
Трехбуквенный символ |
Однобуквенный символ |
Мнемонический ключ к однобуквенному символу |
Относительное содержание в белках Е. coli, % [19] |
Молекулярная масса остатка при pH 7 |
Значение рК боковой цепи [19] |
Значение AG переноса боковой цепи из воды в этанол при 25°С, ккал/моль [16] |
|
Алании |
Ala |
А |
Alanine |
13,0 |
71 |
-0,5 |
|
|
Глутаминовая кислота |
Glu |
E |
gluEtamic acid |
128 |
4,3 |
||
|
Глутамин |
Gin |
Q |
Q-tarninе |
10,8 |
128 |
||
|
Аспарагиновая кислота |
Asp |
D |
asparDic acid |
9,9 |
114 |
3,9 |
|
|
Аспарагин |
Asn |
N |
asparagiNe |
114 |
|||
|
Лейцин |
Leu |
L |
Leucine |
7,8 |
113 |
—1,8 |
|
|
Глицин |
Glу |
G |
Glycine |
7,8 |
57 |
||
|
Лизин |
Lys |
К |
перед L |
7,0 |
129 |
10,5 |
|
|
Серин |
Ser |
S |
Serine |
6,0 |
87 |
+0,3 |
|
|
Валин |
Val |
V |
Valine |
6,0 |
99 |
-1,5 |
|
|
Аргинин |
Arg |
R |
aRginine |
5,3 |
157 |
12,5 |
|
|
Треонин |
Thr |
T |
Threonine |
4,6 |
101 |
-0,4 |
|
|
Пролин |
Pro |
P |
Proline |
4,6 |
97 |
||
|
Изолейцин |
Ile |
I |
Isoleucine |
4,4 |
113 |
||
|
Метионин |
Met |
M |
Methionine |
3,8 |
131 |
-1,3 |
|
|
Фенилаланин |
Phe |
F |
Fenylalanine |
3,3 |
147 |
-2,5 |
|
|
Тирозин |
Tyr |
Y |
tYrosine |
2,2 |
163 |
10,1 |
-2,3 |
|
Цистеин |
Cys |
C |
Cysteine |
1,8 |
103 |
||
|
Триптофан |
Trp |
W |
tWo rings |
1,0 |
186 |
—3,4 |
|
|
Гистидин |
His |
H |
Histidine |
0,7 |
137 |
6,0 |
-0,5 |
|
Средняя масса |
108,7 |
||||||
а Дополнительные трехбуквенные символы: Asx, Glx — либо кислота, либо амид. Аминокислотный остаток—HN—CHR—СО есть часть аминокислоты (рис. 1.2,а), входящая и пептидное звено; R — боковая цепь (рис. 1.1). Дополнительные однобуквенные символы: В = Asx, Z = Glx, X = неизвестный или минорный аминокислотный остаток.
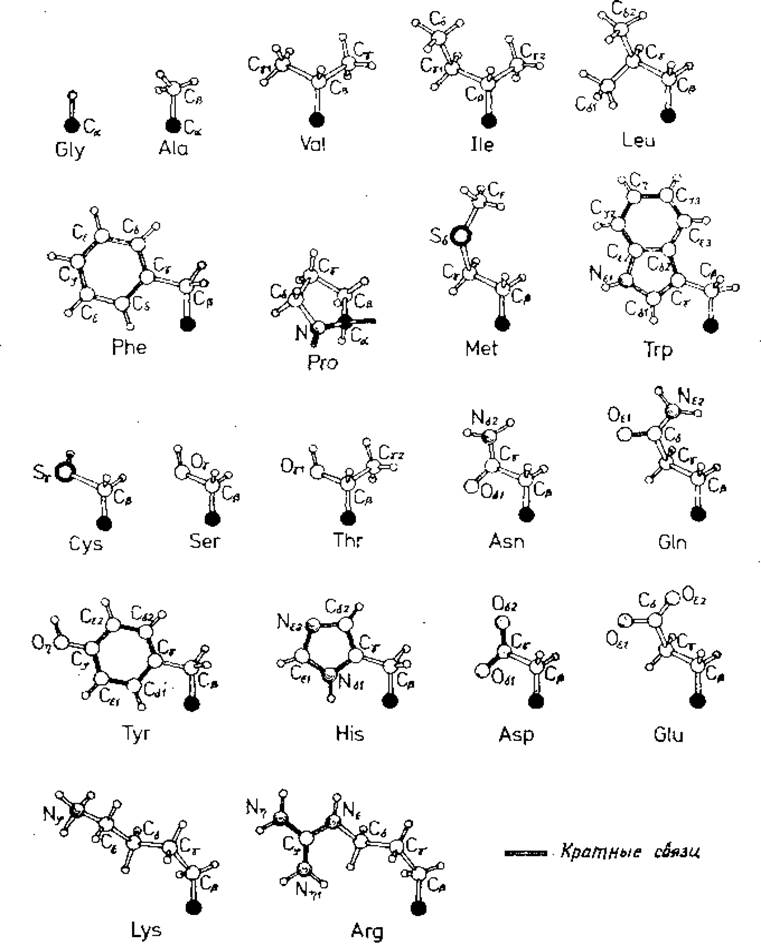
Рис. 1.1. Боковые цепи 20 канонических аминокислот.
Для пролина показана часть основной цепи. Все остальные боковые цепи показаны отходящими от Са -атомов главной цепи. Названия остатков даны в трехбуквенных обозначениях. Обозначения атомов даны согласно номенклатуре IUРАС—1UB от 1969 г. [21]. Основная цепь в Pro зачернена. Все Са -атомы зачернены.
Наше представление о последующей молекулярной эволюции ограничивается пока что более или менее обоснованными догадками. Несмотря на то что самовоспроизведение вначале должно было быть малоэффективным, молекулы, находясь в жестких условиях эволюции, где выживают лишь наиболее приспособленные системы, должны были стремиться к усовершенствованию автокатализа. Можно предположить, что такое усовершенствование начиналось с «ферментов», образовавшихся из нуклеиновых кислот — осколков самих автокаталитических молекул. По-видимому, рибосомная и транспортная РНК — остатки таких катализаторов. Позже ферменты образовавшиеся из нуклеиновых кислот были вытеснены более эффективными белковыми ферментами.
Линейный набор стандартных элементов со стандартными связями. Белковые ферменты возникли по чрезвычайно простой организационной схеме. Аминокислотная последовательность полипептидной цепи белка есть коллинеарное и единственное представление нуклеотидной последовательности исходной нуклеиновой кислоты. Три соседних нуклеотида кодируют одну аминокислоту (рис. 1.5, б). Таким образом, полипептиды сходны с нуклеиновыми кислотами в том, что это линейные цепные молекулы, построенные из стандартных элементов с одной стандартной связью. Это обеспечивает простое и универсальное «считывание» с нуклеиновых кислот в процессе синтеза полипептидов. Простота линейных систем широко используется, в частности, в электронно-вычислительной технике, где хранение и вызов информации обычно осуществляются с помощью одномерных блоков, записанных в стандартной форме на линейных носителях, например магнитных лентах.
В нуклеиновых кислотах, как и в белках, стандартизованы не только связи, но и атомные группы, образующие скелет цепи; в полипептидах все 20 аминокислотных остатков относятся к a-типу и имеют L-конфигурацию Са-атома (рис. 1.2,а). Все различия, а значит, и вся информация сводятся к довольно коротким боковым цепям.
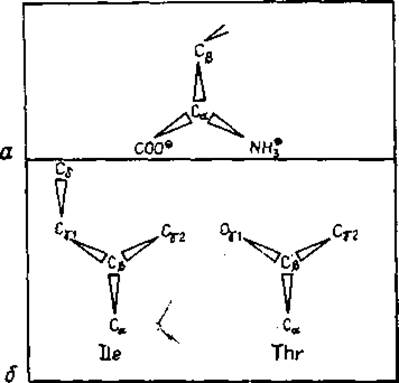
Рис. 1.2. Асимметрические атомы углерода, встречающиеся в канонических аминокислотных остатках. Проекция от атома водорода к атому Са или Сβ соответственно, что противоположно направлению в схеме Кана — Ингольда — Прелога [41].
а — обычный L-изомер а-аминокислоты. Абсолютная конфигурация S при Сχ в обозначениях Кана— Ингольда—Прелога, б —конфигурация при Са -атоме изолейцина (S) и С3 -атоме треонина (R).
Необходимость самопроизвольного свертывания. После синтеза на рибосоме полипептидная цепь самопроизвольно свертывается в определяемый аминокислотной последовательностью глобулярный белок, принимая состояние с наименьшей свободной энергией. Возможно, что свертывание начинается уже в ходе синтеза. Характер свертывания образующейся цепи определяет специфичность белка. Пространственная самоорганизация молекулы значительно упрощает общую схему, так как в противном случае потребовались бы «морфогенетические ферменты» или «ферменты, способствующие свертыванию». Поскольку возможно огромное число способов свертывания цепи, то возникла бы потребность в большом числе таких вспомогательных ферментов.
Допустим, что структуры строятся не путем спонтанного свертывания, а, например, из небольшой молекулы-ядра путем ковалентного присоединения последующих фрагментов. Даже в случае наиболее эффективной схемы, показанной на рис. 1.3, такой процесс потребовал бы двух ферментов для обработки каждого промежуточного продукта, т. е. в среднем по два фермента на образующуюся молекулу. Таким образом, для получения самоподдерживающейся системы все образующиеся на промежуточных стадиях молекулы использовались бы в качестве ферментов, каждый из которых должен был бы катализировать две различные синтетические реакции. Однако в существующих организмах у каждой молекулы наблюдается, вообще говоря, только одно ферментативное действие. К тому же очевидно, что подобная система оказалась бы слишком чувствительной к ошибкам и почти не имела бы шансов эволюционировать в первичной химической массе [6]. Этот пример позволяет оценить простоту, присущую спонтанному свертыванию.
Однако не все полипептидные цепи свертываются самостоятельно. Некоторые из рибосомных белков очень вытянуты и имеют мало внутренних контактов [7]. В этом случае цепь принимает свою окончательную конформацию, прикрепляясь к другой молекуле, а именно к нуклеиновому ядру рибосомы. Эти, по-видимому, очень древние цепи отражают то положение, которое существовало в самом начале образования белков; рибосомы прекрасно сохранились в ходе эволюции. Подобная стабильность следует из центральной роли рибосом в жизнедеятельности организма. Любое изменение в рибосоме имело бы разрушительные последствия, оставляя очень мало шансов на выживание [3, 4].
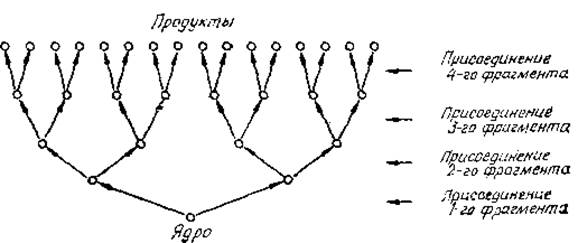
Рис. 1.3. Гипотетическое образование молекулярной структуры путем последовательного присоединения различных фрагментов к молекуле-ядру или путем направленной модификации молекулы предшественника.
Чтобы получить различные структуры, каждое присоединение или модификация должны быть специфическими, что означает необходимость специфического ферментативного воздействия. На четвертой стадии, когда образуются 24=16 различных структур, необходимы 2+4+8+16=30 = 25—2 воздействий.
Канонические аминокислоты могли быть отобраны на начальных стадиях жизни. Набор стандартных звеньев полипептидной цепи состоит из 20 аминокислотных остатков (рис. 1.1, табл. 1.1). Чтобы оказаться отобранными, эти аминокислоты должны были быть в среде, окружавшей первичные автокаталитические нуклеиновые кислоты. Так, по-видимому, и было, что подтвердили некоторые модельные эксперименты [3, 8], где газовую атмосферу, которая могла соответствовать реальной атмосфере на ранних стадиях развития Земли, подвергали воздействию электрической или радиационной энергии. При этом обычно получали рацемическую смесь L- и D-аминокислот (рис. 1.2,а) a-типа наряду с ß-аминокислотами (рис. 1.4) и другими соединениями.
L-Конфигурация отобрана случайно. Какой смысл заложен в выборе именно L-конфигурации Са-атома? Мы понимаем, что обе Са-конфигурации равновероятны; но механизм синтеза цепи требовал вполне определенной конфигурации, иначе синтез оказался бы слишком сложным и не выдержал бы конкуренции. Однако явной причины для предпочтения L-конфигурации ее зеркальному отображению, по-видимому, нет. Правда, было показано, что внутренняя асимметрия в распределении продуктов при ß-распаде проявляется через молекулярную асимметрию путем предпочтительного разрушения D-аминокислот [9]. Но наблюдаемый эффект (несколько процентов) слишком слаб для объяснения отбора. По- видимому, выбор произошел случайно, а не вследствие немного более высокой концентрации среди исходных продуктов L-аминокислот. На последующих этапах D-система оказалась подавленной более развитой l-системой. Не исключено также, что обе системы развивались параллельно и L-система победила благодаря более удачным флуктуациям под действием внешних факторов, влияние которых, по-видимому, значительно превосходило влияние незначительного различия концентраций аминокислот.
Рис. 1.4. Гипотетическая основная цепь, состоящая из ß-амииокислот. Вращение вокруг связей Са—Сβ и Сβ—N достаточно свободно, что делает цепь слишком подвижной. Это также относится к случаю, когда боковые цепи R присоединены к Сβ-атому, а не к Са.
ß-Аминокислоты не подходят. Другой аспект указанных модельных экспериментов состоит в получении ß-аминокислот (рис. 1.4) в количествах, сравнимых с аминокислотами а-типа [8]. Во многих отношениях ß-аминокислоты сходны с а-аминокислотами, однако образующаяся полипептидная цепь будет содержать связи Са—Сβ, допускающие дополнительное свободное вращение. Как показано в разд. 8.1, такая подвижность препятствует самопроизвольному свертыванию цепи. Таким образом, смысл отбора а-аминокислот очевиден.
Трансляционный механизм фиксирует набор типов аминокислот.
Почему все живое на Земле использует один и тот же набор аминокислот? Этот вопрос связан с трансляцией нуклеотидных последовательностей в аминокислотные последовательности, использующей так называемый генетический код (рис. 1.5, б). Генетический код универсален, потому что он находится в самом центре организационной схемы жизни. Любое изменение в коде существенно нарушает схему и обычно приводит к вымиранию организмов. Поэтому код, а значит, и типы аминокислот исключительно тщательно сохраняются. Нет никаких данных о том, что когда-либо существовали организмы с другими аминокислотами или с другими кодами.
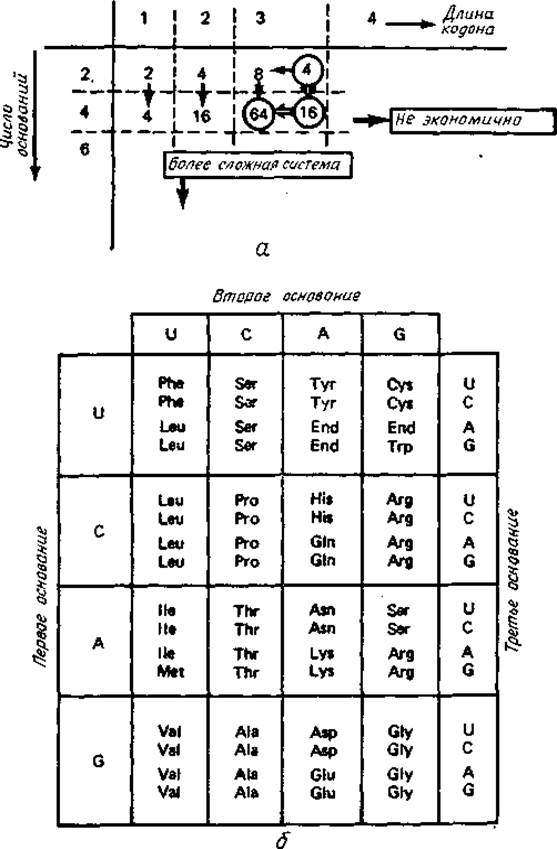
Рис. 1.5. Генетический код трансляции нуклеотидной последовательности в аминокислотную последовательность.
а — число кодируемых аминокислот как функция числа различных нуклеотидных оснований и длины кодона. Стрелки указывают возможные направления эволюции. Исходя из существующего кода, эволюция должна была следовать пути, отмеченому кружочками. б — таблица генетического кода, связывающая нуклеотидные триплеты с аминокислотами.
Почему число отобранных типов аминокислот равно именно 20? Этот вопрос также связан с механизмом трансляции. На рис. 1.5, а в порядке дискуссии даны некоторые трансляционные схемы существующего генетического кода. При дублетном варианте (длина кодона равна двум нуклеотидам) с помощью четырех разных нуклеотидов можно закодировать 42 = 16 аминокислот. Однако для длины кодона природа выбрала не два, а три нуклеотида. Для пояснения этого факта напомним, что длина кодона связана с решающим шагом в трансляции — опознанием нуклеотидной последовательности информационной РНК путем спаривания оснований нуклеотида с небольшой доставляющей аминокислоты транспортной РНК. Можно предположить, что при дублетном коде не оказалось оснований с достаточно большими константами ассоциации, и поэтому кодон должен был увеличиться до триплета, чтобы обеспечить специфическое узнавание. С помощью четырех различных нуклеотидов триплетный код может распознавать 43 = 64 аминокислоты. Однако используются только 20 аминокислот. Для объяснения этого факта нужно предположить, что генетический код развивался и что его эволюция остановилась на полпути.
По-видимому, генетический код сформировался на очень ранних стадиях жизни. Как обсуждалось ранее, изменения генетического кода предельно заторможены. Так, совершенно невозможно изменение длины кодона, поскольку это уничтожило бы всю накопленную генетическую информацию и привело бы к катастрофе. Однако на очень ранних стадиях эволюции, когда организмы были значительно менее совершенны, чем теперь, изменение числа нуклеотидов или аминокислот было, по-видимому, реальным, при условии что оно происходило постепенно. Именно таким образом можно представить себе эволюцию кода в течение определенного периода.
Эта идея подтверждается значительной вырожденностью третьей позиции кодона (рис. 1.5, б). Наиболее вероятной начальной точкой существующего является, по-видимому, триплетный код, использующий два комплементарных нуклеотида. В этом случае значимы только первые две позиции каждого кодона, так что один триплет кодирует лишь четыре разные аминокислоты. На следующем этапе эволюции добавилась еще одна пара комплементарных нуклеотидов, что дало возможность кодировать 16 аминокислот. Наконец, приданием значимости третьей позиции кодона была введена некоторая вырожденность. Когда организмы стали настолько совершенными, т. е. настолько конкурентоспособными, что любое изменение типа хотя бы одной аминокислоты оказывалось опасным, а иногда и летальным, генетический код остановился в своем развитии. Таким образом, было зафиксировано число аминокислотных остатков, равное 20.
Сравнение существующих метаболических путей образования аминокислот с генетическим кодом показывает, что связанные метаболически между собой аминокислоты коррелируют также и в отношении их кодонов [10]. Это делает весьма привлекательной идею параллельной эволюции генетического кода и метаболизма, а также указывает на наличие исторической иерархии аминокислот. Более простые аминокислоты, как Gly, Ser, Ala, Asp и Glu, считаются ранними в отличие от более сложных аминокислот, например Met, His и Asn. Однако последовательное появление аминокислот не отражено в существующих белковых структурах, поскольку аминокислотные остатки белков в известной мере заменяемы; поэтому корреляция с ранними периодами жизни в настоящее время вряд ли правомерна.