Основы биоинформатики - Огурцов А.Н. 2013
Информационные принципы в биотехнологии
Секвенирование биологических последовательностей и экспрессия генов
Определение сиквенса
Клон - это скопированный фрагмент ДНК, который идентичен матрице, с которой он был получен. Процесс определения нуклеотидной последовательности клонов позволяет выполнить анализ целой последовательности ДНК. По окончании эксперимента по клонированию некоторого гена, последовательность которого уже известна, необходимо удостовериться в том, что клонированная последовательность действительно идентична опубликованной расшифровке.
Исходный клон кДНК синтезируют с помощью матрицы мРНК. Затем этот клон секвенируют.
Расшифровка последовательностей клонов, взятых с физической карты генома (рисунок 40(b)), осуществляется путём сборки целого генома, секвенированного методом дробовика. Секвенирование целого генома методом дробовика проводят следующим образом (рисунок 68).
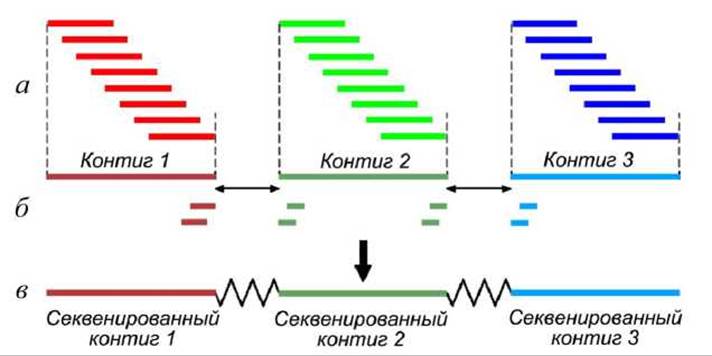
Рисунок 68 - Сборка каркаса (scaffold), секвенированного методом дробовика
Сначала на основании анализа уникальных перекрытий между считываниями последовательностей клонов строят отдельные контиги (рисунок 68(a)). Затем считывают концевые участки спаренных концов контигов (рисунок 68(6)), в результате чего правильно упорядочивают и ориентируют контиги, а также перекрывают пропуски между ними и объединяют их в более крупные единицы, называемые каркасами Сscaffolds) (рисунок 68(b)).
Внедрение технологии флуоресцентного секвенирования привело к ускорению темпов накопления данных о последовательностях ДНК (рисунок 41). Теперь за тот же промежуток времени может быть выполнено большее число реакций секвенирования, а протоколы стали лучше отвечать условиям автоматизации. Если реакции протекают во флуоресцентном геле, то индуцированную лазером флуоресценцию непосредственно регистрирует компьютер.
Обычно гель-электрофорез проводят на 36 параллельных дорожках. Выходная информация представлена рядом закодированных цветом пиков, над которыми расположена строка знаков, обозначающих основания (рисунок 42). Если интерпретирующее хроматограмму программное обеспечение не может определить, какое основание должно быть названо в определённой позиции, в таком случае появляется знак пробела "-". В конечном файле данных секвенирования такие неопределённые позиции обозначены буквой "N".
Выборка клонов отбирается из библиотеки наугад - например, 10 000 из библиотеки объёмом 2 миллиона клонов. Для того чтобы инициировать 10 000 реакций секвенирования и затем провести их на автосеквенторах, выполняется сложная автоматизированная операция секвенирования. Итоговые данные загружаются в базу данных для дальнейшего анализа.
Идеальный результат - это набор из 10 000 последовательностей, каждая из них имеет длину 200-400 нуклеотидов и представляет некоторую часть последовательности каждого из 10 000 клонов.
В действительности некоторые реакции секвенирования вообще не получатся, некоторые производят недостаточно содержательные данные, а некоторые выдают данные неприемлемого качества. Последовательности, которые успешно миновали весь этот процесс, и называют ярлыками экспрессируемых последовательностей EST (Expressed Sequence Tags).
Полученные EST-ярлыки помещают в GenBank, EMBL и DDBJ. Доступ к EST-ярлыкам открыт через все эти базы данных. Те же самые EST-ярлыки находятся в базе данных dbEST (Database of Expressed Sequence Tags), поддерживаемой NCBI.